
Parallel Tracking and Mapping (PTAM)
Published:
Summary obtained from the 2007 paper Parallel Tracking and Mapping by Georg Klein and David Murray from the Department of Engineering Science, Oxford.
In PTAM, mapping and object tracking is split into two separate tasks processed in parallel threads. One thread handles robust tracking of erratic hand-held camera movement, and the other learns a 3D point cloud of the observed surroundings. PTAM is generally used in AR/VR applications, and is a response to improve upon EKF-SLAM and Fast-SLAM, which are incremental mapping methods.
In many AR applications, extensible tracking is used, which relies on some prior map or object of interest to be known. In PTAM, the goal is to track objects in scene without any prior knowledge, while simultaneously building a map of the environment. With knowledge of its surroundings through generating a map, the algorithm is able to render simulations over the camera frame in realtime. Separating the two tasks allows tracking to no longer be dependant on mapping, and data association between the tasks do not need to be shared. Since they are not dependent, it is not necessary to use every single video frame for mapping, reducing time wasted on filtering and processing the same data frames (i.e. if stationary or minimal/slow movement). In this way, the mapping process can also be sped up to adhere to real-time application limitations. Incremental mapping can also be made more accurate through more computationally expensive batch methods (i.e. bundle adjustment). The paper assumes a hand-held camera scenario, which assumes that 2D feature tracks are not available to initialise features. Thus, an epipolar feature search method is used.
| Bundle Adjustment: The simultaneous refining of 3D coordinates of a scene geometry through minimizing reprojection error between image locations of observed and predicted image points by using nonlinear least-squares algorithms. Used as the last step of a feature-based 3D reconstruction algorithm. Bundle adjustment is a proven method for offline Structure-from-Motion. |
| Epipolar Feature Search: Epipolar geometry is the geometry of stereo vision, in which 2 cameras view a 3D scene from 2 distinct positions. In calculating correspondences between two views/frames, the pixel patches around corners points which lie along the epipolar line in the second view are compared to the generated map points using zero-mean SSD. Instead of searching on an infinite epipolar line, the paper uses a prior hypothesis on the likely depth of new candidate points, which depends on the depth distribution of existing points in the new keyframe. If a match is found, the new map point is triangulated and inserted into the map. |
Hardware and Implementation Notes
The following are the various hardware and settings used by the paper in capturing data:
- Unibrain Fire-i video camera, 2.1mm wide-angle lens
- 640x480 YUC411 frames at 30Hz, converted to 8bpp greyscale (tracking) and RGB (AR display)
- Approx. 1656 frames of live video input is used, simulating various panning motions and shaking (to break tracking)
Implementation Notes:
- Written in C++, with libCVD and TooN (code is not optimised)
- Program is not robust, relying on simple heuristics to remove outliers from the map, and the normal vector used to initialise map patches is not optimized.
- Overall, the 2-stage tracking process increases the robustness to rapid motion, but also increase the tracking jitter. This can be mitigated with implementing adaptive tracking, where the system turns off the coarse tracking stage when the motion model observes the camera to be mostly stationary.
Mapping
The map is a collection of M point features within a world coordinate frame W, and N keyframes taken by the camera at various points in time. Each point feature represents a locally planar textured patch in the world. Each point also has a unit patch normal and a reference to the patch source pixels.
Each of the N keyframes has an associated camera-centred coordinate frame (Ki), and stores a 4-level pyramid of greyscale 8bpp images, each at an increasing level of subsampling. Level 0 stores the full 640x480 px image, and level 3 subsamples it down to 80x60 px. Each point feature in the map also stores its source keyframe (typically the first frame the object was observed). After the 4-level subsampling, FAST-10 corner detection is run on each subsampled level with non-maximal suppression.
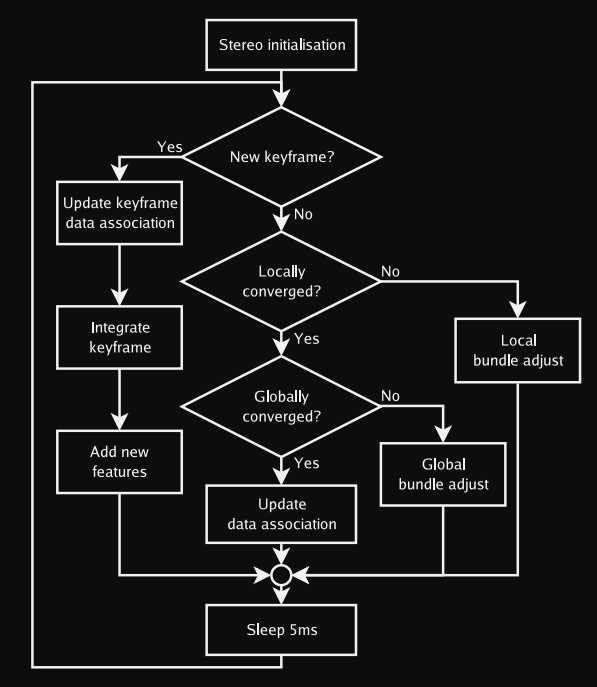 Asynchronous mapping thread (source: paper linked above)
Asynchronous mapping thread (source: paper linked above)
In general, the mapping process follows the following steps:
- Map initialisation using 5-point stereo algorithm. 1000 2D patch-tracks are generated at the lowest pyramid level per frame. User presses a button to record a keyframe.
- RANSAC is used to rotate and translate the initial map to z=0
- Keyframes are added when tracking quality is good, time since last keyframe has exceeded 20 frames, and camera is a minimum distance away from the nearest keyframe recorded (depends on mean depth of observed features). Correspondences between two close keyframes are calculated using epipolar search and the map is further updated.
- Levenberg-Marquardt bundle adjustment with Tukey M-estimator is applied to further refine the map. This iteratively adjusts the map to minimise the objective function. Complexity scales with map size. Adjustment is interrupted if a keyframe needs to be added during adjustment.
- After bundle adjustment has converged and no new keyframes are needed, data association refinement is done to improve the map. New measurements are made in old keyframes to check for new features in old frames, or re-measuring outlier features before deletion or re-insertion.
Tracking
Tracking works on the assumption that some 3D point cloud map has already been creating in the mapping step as described above. In tracking, the system receives images from the camera and calculates realtime estimate of the camera pose relative to the map. A decaying velocity model (similar to alpha-beta constant) is used to generate the prior pose estimates. With this estimate, any AR graphic can be drawn on top of the video frame. Tracking is a 2-stage process performed at every frame update:
- Prior pose estimate is generated from a motion model.
- Map points are projected into the image according to the frame’s prior pose estimate.
- Search for a small number (50) of the coarsest-scale features
- Camera pose is updated from coarse matches
- Search and re-project large number (1000) of points
- Calculate final pose estimate from all matches
Tracking Evaluation and Failure Recovery
Errors in tracking is largely inevitable. The tracking system estimates its quality at every frame, using the fraction of feature observations which have been successful. If the fractions falls below a certain threshold, tracking quality is poor and tracking continues as normal but stops any new keyframes from being used to update the map. This assumes that the new frames would be of poor quality (motion blur, occlusion, incorrect position estimate etc.). If the fraction falls even lower (another threshold), for more than a few frames, tracking is considered lost and a tracking recovery procedure is initiated. The recovery procedure calculates a new pose estimate and tracking resumes as per normal.
Key Summary
In PTAM,
- Tracking and Mapping are separated and run on separate threads
- Mapping uses keyframes processed using batch techniques like bundle adjustment
- Map is densely initialised using stereo cameras using a 5-point algorithm
- New points are initialised with an epipolar search
- Thousands of points are mapped
- Does not need markers, pre-made maps, known templates, or inertial sensors
The paper reports that
- Tracking completes in around 20ms regardless of increasing map size. Tracking time can be affected by map size, number of features currently in field of view, image corner density, and distribution of features over pyramid levels.
- Mapping does not scale well with increasing map size (largest tried was 11000 map points and 280 keyframes). For very large maps, the system’s ability to add more new keyframes and map points is impaired. Largest recommended is 6000 points and 150 keyframes. With bigger maps, the system needs longer time to finish bundle adjustment (camera must be stationary during this).
- Since mapping and tracking are asynchronous, results are not repeatable.
In application,
- PTAM does not require the ‘SLAM wiggle’. Instead, PTAM works best when the camera is focused on a point of interest, pauses briefly, then proceeds to the next point of interest/different perspective of the same point.
- The multiple pyramid levels greatly improves tolerance to rapid motion and motion blur, and also allows mapped points to be useful across a wide range of distances (fast zooming in/out). This results in increased number of features, which also improves performance when handling occlusion or data corruption.
- Compared to EKF-SLAM, PTAM is more resilient to motion changes, and scales differently with increasing map size (EKF-SLAM experience dropping frame rates, PTAM does not but the rate of exploration of new parts of the environment is slowed down due to the change in user behaviour the algorithm necessitates.)