
Segmentation Tasks
Published:
Segmentation is a popular vision problem that is concerned with analysis and object or scene understanding of the contents of a given input scene. Most commonly, this is used with images, but segmentation can also be performed on a range of datatypes such as videos or 2D and 3D point clouds. The ability of segmentation models to detect objects and identify their location makes these models incredibly useful in projects involving autonomous machines and mapping and localization.
Types of Segmentation
There are a few types of segmentation tasks, each concerning a different level of granularity within it’s classification objective. The main difference between these tasks are the types of datasets (particularly how they are labelled), and their end application use. This section provides a brief overview of the different kinds of segmentation: Semantic, Instance and Panoptic.
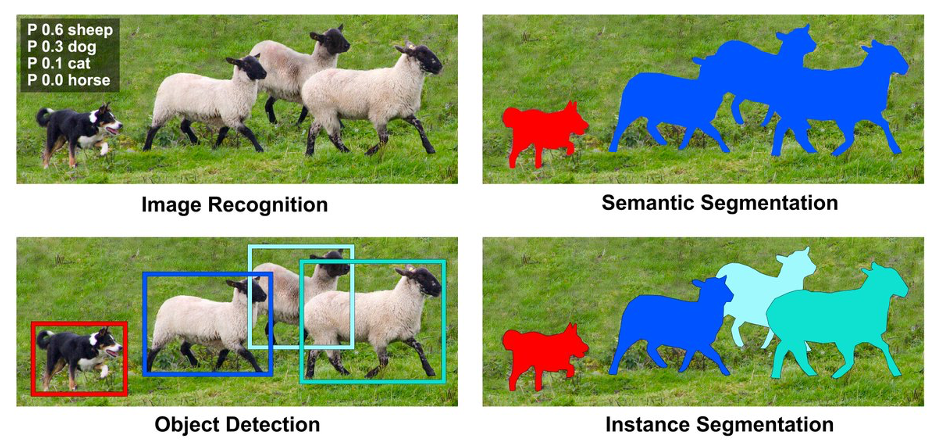 Output comparisons between different visual perception networks (source: University of Waterloo)
Output comparisons between different visual perception networks (source: University of Waterloo)
Semantic Segmentation
Most prominent is Semantic Segmentation, which performs pixel-wise classification on an image, and identifies the location of objects within the image through masks. This sets it apart from object detection, which only says ‘This image has sheep and dogs, and maybe cats, but no horses’, but does not tell you where these objects are. This is due to object detection models performing a sort of pattern matching (over a group of pixels) through learnt feature maps.
A semantic segmentation model functions as such:
- Extract features in training data
- Localize objects through bounding boxes
- Training to group pixels by learning the segmentation mask of objects.
In this way, objects are identified by local groups in an image, but does not distinguish individual instances of the actual object. Semantic segmentation is often used to study objects that are more amorphous.
Applications of Semantic Segmentation:
- Autonomous Driving: Detecting lanes, pedestrians etc.
- Geo Sensing: Satellite imagery and monitoring areas of deforestation and urbanization
- Medical: Detecting abnormalities in medical scans
Instance Segmentation
Instance Segmentation combines object detection and semantic segmentation. It identifies all instances of a class, and can demarcate each object as separate instance of the same class. Compared to semantic segmentation, the output of instance segmentation is more detailed, able to recognize objects as sheep, and also able to distinguish each sheep as a separate sheep, not simply a blob of sheep pixels (which may in fact include multiple sheep). However, this also means that in essence, each sheep is treated as a separate sheep class on its own.
An Instance segmentation model functions as a combination of 2 methods:
- Object Detection - find bounding boxes for every object
- Semantic Segmentation - find object masks for each object
In implementation, there are 2 approaches:
- Top-down: Learn semantic point features first, then group into separate instances
- Uses approach similar to Mask R-CNN, where instances are detected as bounding boxes, then mask segmentation is performed on each box individually.
- Bottom-up: Detect object instances then refine semantic mask
- Uses Contrastive Learning; points are mapped to a high-dimensional feature space where features of the same instance are close together, and far apart from others.
Applications of Instance Segmentation:
- Medical: Identify tumors in MRI scans etc.
- Satellite Imagery: Counting cars, detecting ships for maritime security etc.
- Robotics: Self-supervised learning to segment observations into individual objects
Panoptic Segmentation
Panoptic Segmentation is concerned with scene understanding, and combines semantic and instance segmentation. It identifies objects with respect to its class labels, and also identifies all individual instances of the object in the scene. These class labels includes both countable objects with properly defined geometry (i.e. people, cars, animals), as well as things that have no defined geometry but are easily identified by texture (i.e. sky, road, water).
A Panoptic Segmentation model functions as such:
- Semantic Segmentation - Separate each object in the image into independent individual part, then label each part
- Instance Segmentation - Classify the objects
 Comparison between panoptic segmentation and others (source: Panoptic Segmentation)
Comparison between panoptic segmentation and others (source: Panoptic Segmentation)
Summary
In general, the different visual perception tasks can be characterized as such:
| Image Classification/Recognition | Predict some class label(s) that describe the contents of input |
| Object Detection | Image classification + find bounding boxes of each object |
| Semantic Segmentation | Pixel-wise classification of input, then group pixels into objects. |
| Instance Segmentation | Object detection + semantic segmentation (find individual objects, then within each box, differentiate object from background and learn its mask) |
| Panoptic Segmentation | Semantic + instance segmentation |